
We want to share the method we use to analyze the quality of the training data that we use for our Automatic Speech Recognition model, which is divided into the following steps:
Step 1: Calculate the size of the population sample, for this we use a non-probability sampling using the following formula:
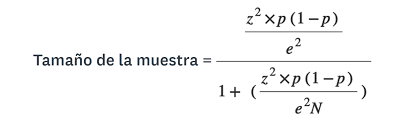
Step 2: Obtaining the sample size, we proceeded to carry out the evaluation of the data in a random way, obtaining in our largest dataset a result of 91.5% positive samples.
Step 3: Complementing with a tool for estimating the error of a proportion, we were able to obtain a relative error of 2.73%, very encouraging results.